|
Email | CV | Google Scholar | LinkedIn I am a Senior Research Scientist at Adobe Research. My works focus on data-driven approaches to visual content understanding and generation. Before returning to Adobe, I also worked as a senior research scientist at ByteDance Research and SEA AI Lab (SAIL). Prior to that, I worked with Professor Feng Liu in the Computer Graphics & Vision Lab at Portland State University. I am actively looking for research interns and collaborators. Please feel free to drop me an email if you are interested. |

|
|
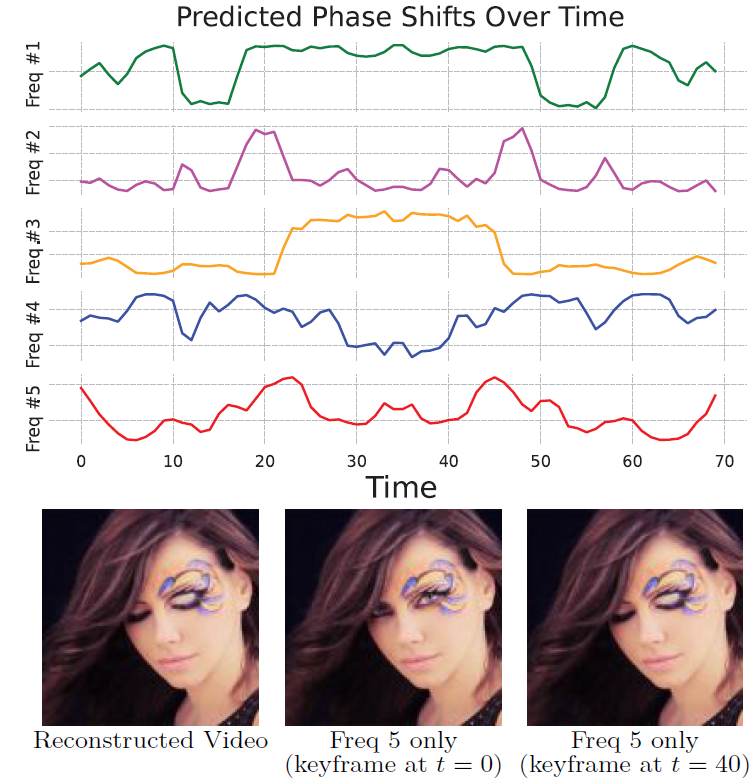 |
Long Mai, Feng Liu CVPR, 2022 (Oral Presentation) Project Page | Paper | Video By exploiting the relation between the phase information in sinusoidal functions and their displacements, we incorporate into the conventional image-based INR model a phase-varying positional encoding module, and couple it with a phaseshift generation module that determines the phase-shift values at each frame. The resulting model is capable of learning to interpret phase-varying positional embeddings into the corresponding time-varying content. At inference time, manipulating the phase-shift vectors can enable temporal and motion editing effects. |
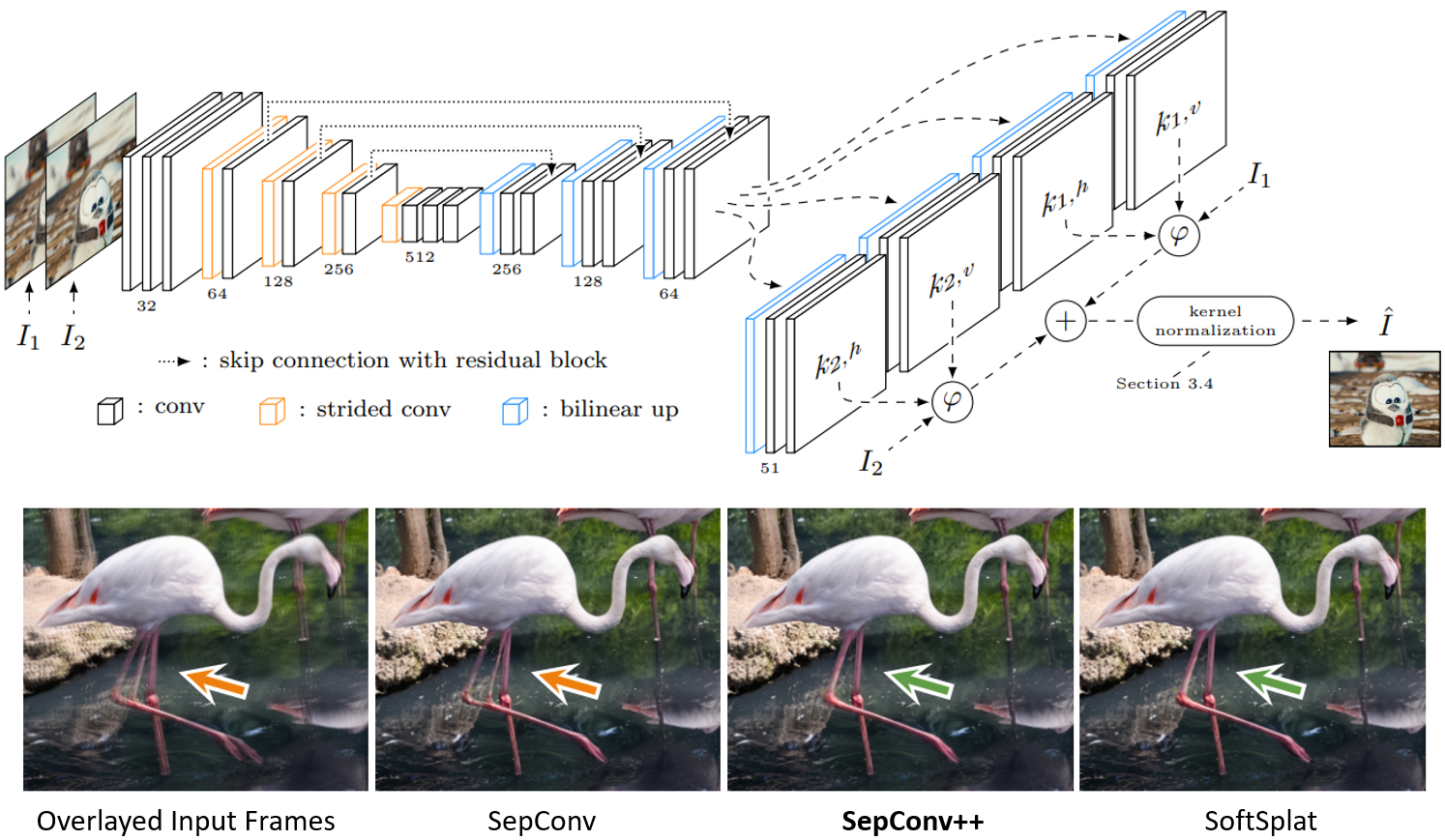 |
Simon Niklaus, Long Mai, Oliver Wang WACV, 2021 Project Page | Paper | Video | Code We show that it is possible to achieve near state-of-the-art video frame interpolation results with our good old adaptive separable convolutions technique, by a subtle set of low level improvements. Our intuitive but effective techniques can potentially be applied to other applications of adaptive convolutions such as burst image denoising, joint image filtering, or video prediction. |
 |
S. Mahdi H. Miangoleh*, Sebastian Dille*, Long Mai, Sylvain Paris, Yağız Aksoy CVPR, 2021 Project Page | Paper | Video | Code We present a double estimation method that improves the whole-image depth estimation and a patch selection method that adds local details to the final result. We demonstrate that by merging estimations at different resolutions with changing context, we can generate multi-megapixel depth maps with a high level of detail using a pre-trained model. |
 |
Wei Yin, Jianming Zhang, Oliver Wang, Simon Niklaus, Long Mai, Simon Chen, Chunhua Shen CVPR, 2021 (Oral Presentation, Best Paper Finalist) Paper | Video | Code Recent state-of-the-art monocular depth estimation methods cannot recover accurate 3D scene structure due to an unknown depth shift and unknown camera focal length. To address this problem, we propose a two-stage framework that first predicts depth up to an unknown scale and shift from a single monocular image, and then use 3D point cloud encoders to predict the missing depth shift and focal length that allow us to recover a realistic 3D scene shape. |
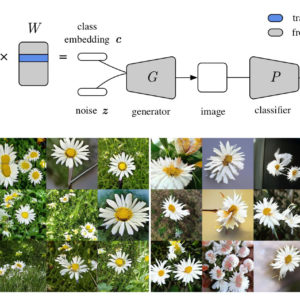 |
Qi Li, Long Mai, Michael A. Alcorn, Anh Nguyen ACCV, 2020 (Oral Presentation, Best Application Paper Honorable Mention) Project Page | Paper | Code In this paper, we propose a simple solution to mode collapse i.e. improving the sample diversity of a pre-trained class-conditional GAN by modifying only its class embeddings. Our method improves the sample diversity of state-of-the-art ImageNet BigGANs. By replacing only the embeddings, we can also synthesize plausible images for Places365 using a BigGAN generator pre-trained on ImageNet, revealing the surprising expressivity of the BigGAN class embedding space. |
 |
Thu Nguyen-Phuoc, Christian Richardt, Long Mai, Yong-Liang Yang, Niloy Mitra NeurIPS, 2020 Project Page | Paper | Code We present BlockGAN, an image generative model that learns object-aware 3D scene representations directly from unlabelled 2D images. Inspired by the computer graphics pipeline, we design BlockGAN to first generate 3D features of background and foreground objects, then combine them into 3D features for the wholes cene, and finally render them into realistic images. Using explicit 3D features to represent objects allows BlockGAN to learn disentangled representations both in terms of objects and their properties. |
 |
Zhuowan Li, Quan Tran, Long Mai, Zhe Lin, Alan Yuille CVPR, 2020 Project Page | Paper We introduce a new task, context-aware group captioning, which aims to describe a group of target images in the context of another group of related reference images. We propose a framework combining self-attention mechanism with contrastive feature construction to effectively summarize common information from each image group while capturing discriminative information between them. |
 |
Ke Xian, Jianming Zhang, Oliver Wang, Long Mai, Zhe Lin, Zhiguo Cao CVPR, 2020 Project Page | Paper | Video | Code We introduce a novel pair-wise ranking loss based on adaptive sampling strategy for monocular depth estimation. The key idea is to guide the sampling to better characterize structure of important regions based on the low-level edge maps and high-level object instance masks. We show that the pair-wise ranking loss, combined with our structure-guided sampling strategies, can significantly improve the quality of depth map prediction. |
 |
Naoto Inoue, Daichi Ito, Yannick Hold-Geoffroy, Long Mai, Brian Price, Toshihiko Yamasaki Eurographics, 2020 Paper | Supp. | Video We present RGB2AO, a novel task to generate ambient occlusion (AO) from a single RGB image instead of screen space buffers such as depth and normal. RGB2AO produces a new image filter that creates a non-directional shading effect that darkens enclosed and sheltered areas. RGB2AO aims to enhance two 2D image editing applications: image composition and geometryaware contrast enhancement. |
 |
Simon Niklaus, Long Mai, Jimei Yang, Feng Liu SIGGRAPH Asia, 2019 Project Page | Paper | Code | Video | Presentation at Adobe MAX 2018 In this paper, we introduce a learning-based view synthesis framework to generate the 3D Ken Burns effect from a single image. Our method supports both a fully automatic mode and an interactive mode with the user controlling the camera. |
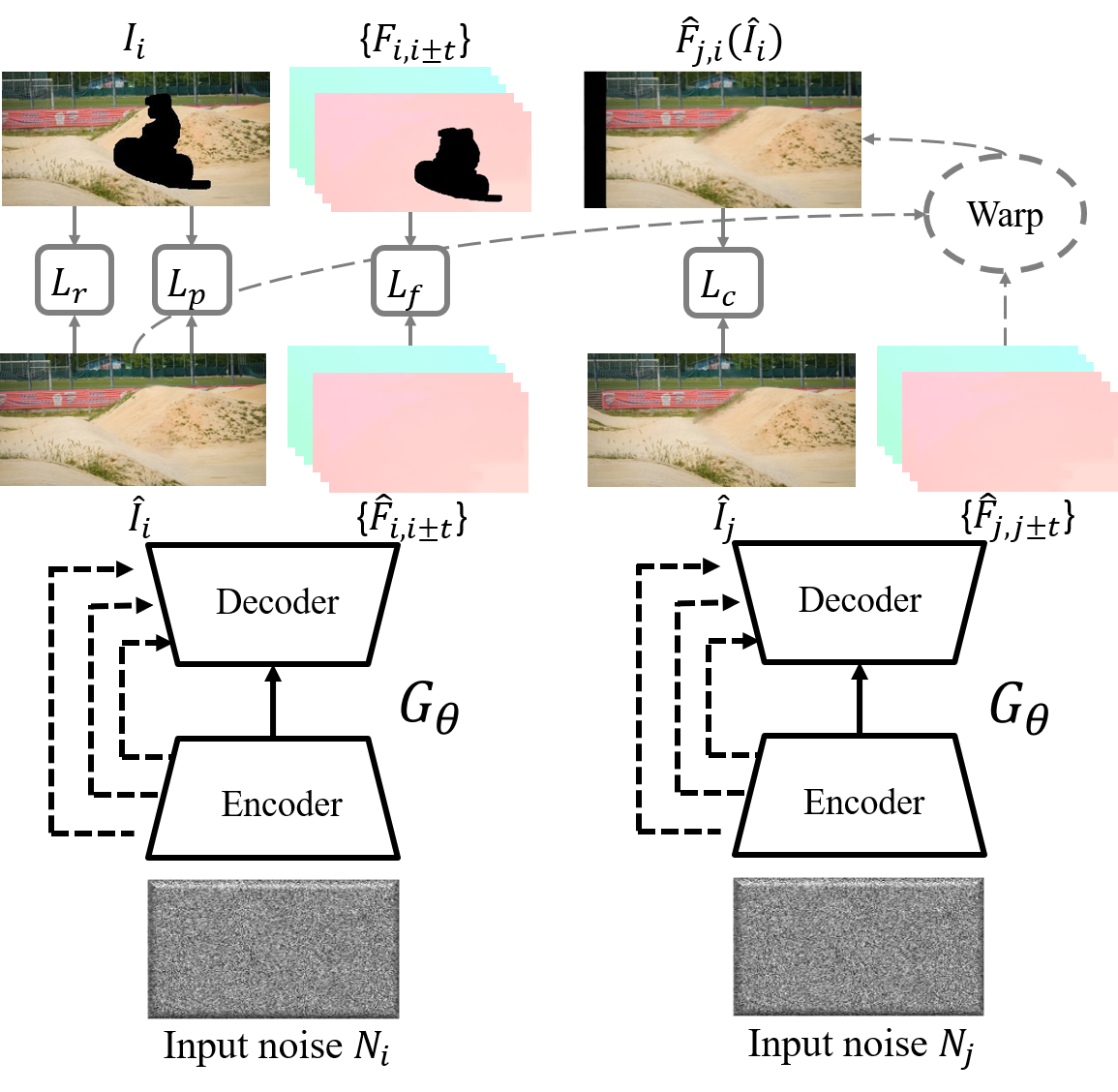 |
Haotian Zhang, Long Mai, Ning Xu, Zhaowen Wang, John Collomosse, Hailin Jin ICCV, 2019 Project Page | Paper | Video We explore internal learning for video inpainting. Different from conventional learning-based approaches, we take a generative approach to inpainting based on internal (within-video) learning without reliance upon an external corpus of training data. We show that leveraging appearance statistics specific to each video achieves visually plausible results whilst handling the challenging problem of long-term consistency. |
 |
Jun Hao Liew, Scott Cohen, Brian Price, Long Mai, Sim-Heng Ong, Jiashi Feng ICCV, 2019 Paper We present MultiSeg, a scale-diverse interactive image segmentation network that incorporates a set of two-dimensional scale priors into the model to generate a set of scale-varying proposals that conform to the user input. our method allows the user to quickly locate the closest segmentation target for further refinement if necessary. |
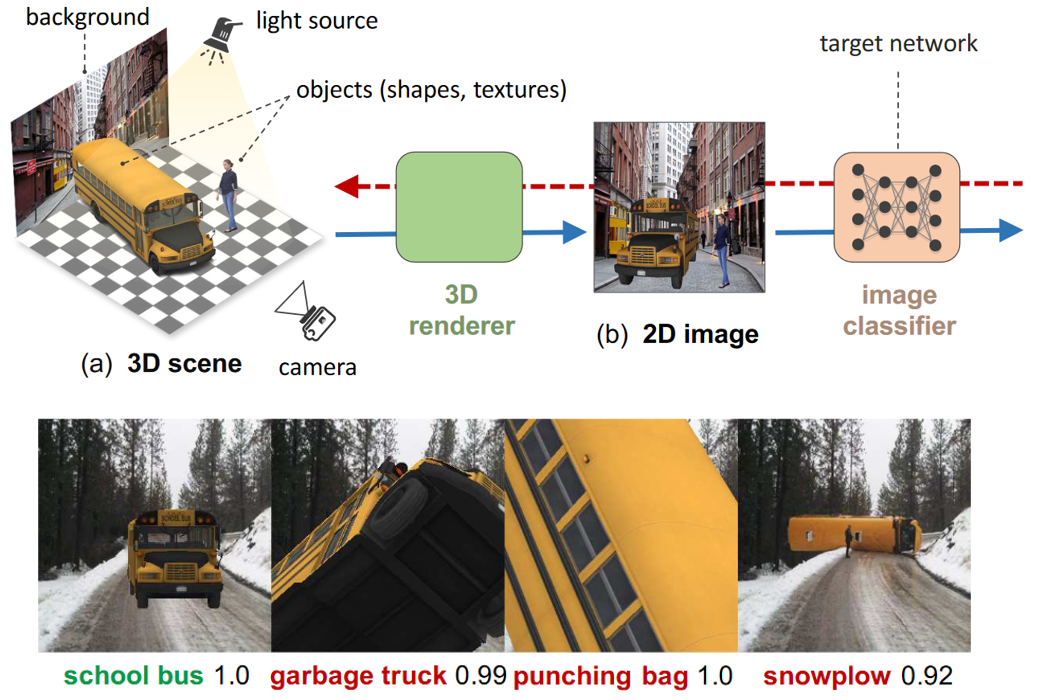 |
Michael Alcorn,Qi Li, Zhitao Gong, Chengfei Wang, Long Mai, Wei-shinn Ku, Anh Nguyen CVPR, 2019 Project Page | Paper | Code We present a framework for discovering DNN failures that harnesses 3D renderers and 3D models. We estimate the parameters of a 3D renderer that cause a target DNN to misbehave in response to the rendered image. Using our framework and a self-assembled dataset of 3D objects, we investigate the vulnerability of DNNs to OoD poses of well-known objects in ImageNet. Importantly, we demonstrate that adversarial poses also transfer consistently across different models as well as different datasets. |
 |
Hoang Le, Long Mai, Brian Price, Scott Cohen, Hailin Jin, Feng Liu ECCV, 2018 Paper In this paper, we introduce an interaction-aware method for boundary-based image segmentation. Instead of relying on pre-defined low-level image features, our method adaptively predicts object boundaries according to image content and user interactions. |
 |
Simon Niklaus, Long Mai, Feng Liu ICCV, 2017 Project Page | Paper | Video | Code We formulate frame interpolation as local separable convolution over input frames using pairs of 1D kernels. Compared to regular 2D kernels, the 1D kernels require significantly fewer parameters to be estimated. Our method develops a deep fully convolutional neural network that takes two input frames and estimates pairs of 1D kernels for all pixels simultaneously. This deep neural network is trained end-to-end using widely available video data without any human annotation. |
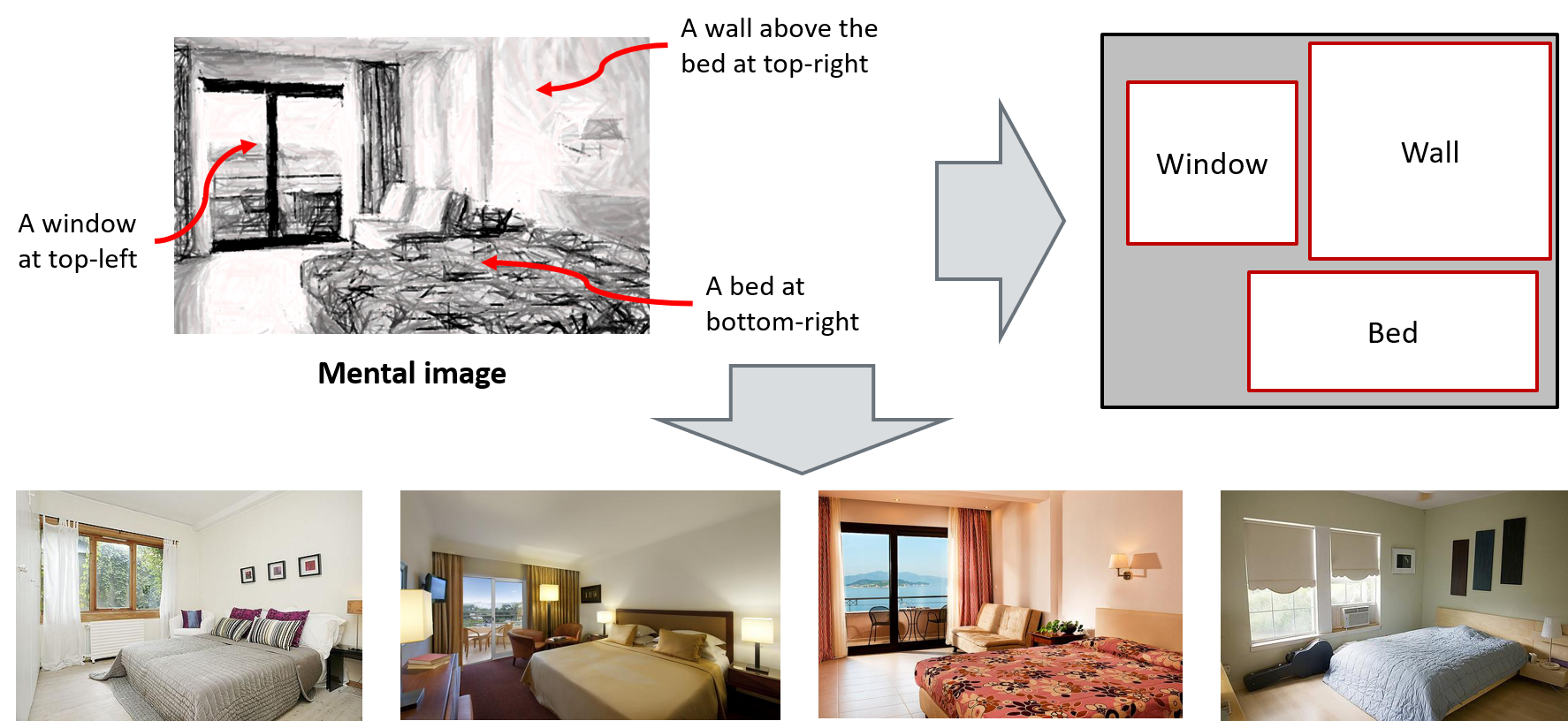 |
Long Mai, Hailin Jin, Zhe Lin, Chen Fang, Jonathan Brandt, Feng Liu CVPR, 2017 (Splotlight Presentation) Paper | Presentation at Adobe MAX 2016 We develop a spatial-semantic image search technology that enables users to search for images with both semantic and spatial constraints by manipulating concept text-boxes on a 2D query canvas. We train a convolutional neural network to synthesize appropriate visual features that captures the spatial-semantic constraints from the user canvas query. |
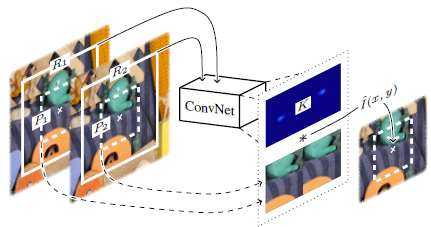 |
Simon Niklaus*, Long Mai*, Feng Liu CVPR, 2017 (Splotlight Presentation) Project Page | Paper | Video Video frame interpolation typically involves two steps: motion estimation and pixel synthesis. Such a two-step approach heavily depends on the quality of motion estimation. We present a robust video frame interpolation method that combines these two steps into a single process. Our method considers pixel synthesis for the interpolated frame as local convolution over two input frames, where the convolution kernel is predicted adaptively using a deep neural network. |
 |
Long Mai, Hoang Le, Feng Liu GI, 2017 Project Page | Paper | Video Image projection is important for many applications. However, perceived distortion is often introduced by projection, which is a common problem of projector systems. Compensating such distortion for projection on non-trivial surfaces is often very challenging. In this paper, we propose a novel method to pre-warp the image such that it appears as distortion-free as possible on the surface after projection. |
 |
Long Mai, Hailin Jin, Feng Liu CVPR, 2016 Project Page | Paper | Code In this paper, we present a composition-preserving deep ConvNet method that directly learns aesthetics features from the original input images without any image transformations. Specifically, our method adds an adaptive spatial pooling layer upon the regular convolution and pooling layers to directly handle input images with original sizes and aspect ratios. |
 |
Long Mai, Feng Liu CVPR, 2015 Project Page | Paper Kernel estimation for image deblurring is a challenging task. While individual kernels estimated using different methods alone are sometimes inadequate, they often complement each other. This paper addresses the problem of fusing multiple kernels estimated using different methods into a more accurate one to better support image deblurring than each individual kernel. |
Long Mai, Feng Liu ECCV, 2014 Paper A wide variety of methods have been developed to approach the problem of salient object detection. The performance of these methods is often image-dependent. This paper aims to develop a method that is able to select for an input image the best salient object detection result from many results produced by different methods. |
|
 |
Long Mai, Yuzhen Niu, Feng Liu CVPR, 2013 Project Page | Paper A variety of methods have been developed for visual saliency analysis. These methods often complement each other. This paper proposes data-driven approaches to aggregating various saliency analysis methods such that the aggregation result outperforms each individual one. |
 |
Long Mai, Hoang Le, Yuzhen Niu, Yu-chi Lai, Feng Liu ACM Multimedia, 2012 Project Page | Paper Simplicity refers to one of the most important photography composition rules. Understanding whether a photo respects photography rules or not facilitates photo quality assessment. In this paper, we present a method to automatically detect whether a photo is composed according to the rule of simplicity. We design features according to the definition, implementation and effect of the rule. |
 |
Long Mai, Hoang Le, Yuzhen Niu, Feng Liu IEEE ISM, 2011 Project Page | Paper The rule of thirds is one of the most important composition rules used by photographers to create high-quality photos. The rule of thirds states that placing important objects along the imagery thirds lines or around their intersections often produces highly aesthetic photos. In this paper, we present a method to automatically determine whether a photo respects the rule of thirds. |